
Intro
From late 2018 until 2023 I worked at various levels as an engineer at a software startup that had it's own hand-rolled
Infrastructure as Code solution, and it's own hand-rolled dependency injection solution.
As I was the person who hand-rolled it I feel some responsibility for the pain and silliness that the many people who
worked there during that time had to experience. Now about 6 months removed from that job there is
a nostalgia about those tools and what they were able to do
Part 1. A Long Obsession
I became aware of Dependency Injection working in a large code-base that didn't use it around 2012. At the time I was starting to really understand unit-testing and finding ways to add unit-tests to the code base that didn't have them. When writing or refactoring code I would often use what, at the time, I called "Poor Mans Dependency Injection" which is just passing all the collaborators for class as arguments to the constructor. This mixed with the Mocking Libraries (Moq) became my standard approach to testing.
I later moved on to another job that did use dependency injection, specifically Spring and at the time Spring with XML declaration files. This was pretty painful but at the same time it felt familiar when it came to unit testing. For a while I stayed up-to-date with what Spring was doing, moving to interfaces for configuration in particular, and I spent some time thinking about Dependency Injection in other programming languages. Then one day we were given the mandate from some ex-twitter people to use an open source twitter framework, and this framework was built around google's Guice DI tooling. Seeing another flavor of Dependency Injection in Java lead me down a bit of a rabbit hole which ended with Dagger.
For those who are not aware Dagger was a Dependency Injection tool, based off the same annotations that Spring and Guice could use, and with largely the same feature set. What made Dagger different was that it could be run as an annotation processor which was a pre-execution phase in Java. Dagger could effectively resolve dependencies and bake that resolution into the jar. The advantage of this is that in a horizontally scaled microservice you wouldn't pay the resolution cost on each startup.
I took inspiration from Dagger and ended up writing my own DI tool in Go when I was learning that language, I never finished it but it used the built-in compiler and Go's special comment syntax to figure out the linking of functions and put them together in a generated file. I would later attempt to write an open source javascript dependency injection tool I called cider, like Guice. It is sitting on NPM but never really did what I wanted it to do.
What I found so compelling with Dagger, and why it's important to this story, is that the people who built were able to make a complete change to the way Dependency Injection systems worked just by thinking about how they were actually being used. Systems like Spring, and even Guice had seperated the configuration from the code, although they'd started to bring those two back together. This meant that by switching out your configuration you could switch out your implementations and change the behavior of the system. That would make it easier to write unit tests since you could change out a dependency with a mock, but that wasn't the original purpose of this separation. In a world with big complex software, that was going to be installed on a bunch of different servers, almost certainly not maintained by you. There was a real advantage in having a way to reconfigure your software by simply trading out different dependencies. Imagine for instance being able to trade out your data facade for one using MySql, Postgres, or Oracle.
What had happened in the years since Spring had come out and when I had started using it was that the software world had changed. Multi-tenancy, Hosted / Managed software, and microservices were all becoming the fashion. With that there was simply no reason to run your software in multiple configurations with the exception of testing. In this context Dagger's move to use an annotation processor and figure out the dependnecy injection graph ahead of time was a smart one.
Part 2. Self Describing Infrastructure
Now at the startup I was working in a system using AWS' serverless resources, specifically Lambda, S3, and Dynamo. At first we initialized these services through a mix of scripting or manual configuration but we quickly moved into CloudFormation for this, initially using the AWS Serverless Application Model (SAM) transformation. While the move to Cloud Formation allowed us to co-locate our templates with our code, and handoff the process of deploying infrastructure changes to Cloud Formation it did leave something to be desired. We had started to expand into more lambda functions, many of which were accessible behind an API Gateway. We were security conscience and knew that ideally each lambda function would be provisioned with an AWS IAM role that was absolutely minimal for what it needed. It was only a matter of time until we made changes to code and forgot to make the equivalent cloud formation change. This got me thinking about the idea of "Self Describing" code. Code that included meta-data, I was initially thinking about a block comment at the top of the file, that would be used to generate the Cloud Formation template. This was an interesting idea but not one worth pursuing at that time.
During a big push to add accounts to our system we built a microservice we called the account service. Unlike every other backend system we'd made up to this point, the account service wouldn't be directly accessible to customers, but rather called through other services. To do this we employed CloudFormation Imports and Exports. This allowed us to create a Cloud Formation stack for our account service, and export the names of lambda functions. Then our consumer service could import those names, creating a deployment time resolved hard-link between the stacks. Much like Dagger with it's build time resolution of dependencies we realized that we could eschew a traditional runtime service locator due to our architecture and the fact that there would only be one right answer in each environment. While this system worked great for production it fell apart in our acceptance testing environment.
Up-till now we'd been able to build isolated stacks that we could spin up a new copy of with each change. We could then test our apis against real resources and teardown the stacks after the test. However with the import directives we now needed to also spin up our dependencies. Testing would require us to have knowledge of the inner working of these other dependencies. While we could muddle through the situation with things depending on our account stack it was obvious that the whole system would fall down if we didn't find a way to address transitive dependencies when testing. This meant that we would need a way to in some cases use an import statement, and in other cases, feed in different data. We were going to need a way to understand templates, and at that point it seemed an opportune moment to re-embrace the idea of "Self Describing" code.
It's worth pointing out that while there was a fairly small task that could have been done to simply build a processor that changed the CloudFormation Templates it felt like a better use of time to go all-in on a big idea since it would also solve issues around things getting out-of-sync between the code and the template.
Looking back on it it's remarkable how close to the 2023 version of the tooling the 2018 version was. I quickly abandoned the idea of using comments and static analysis was too big a task to do in the time I had so instead I went back to what I loved and decided to build a dependency injection tool.
The idea was pretty basic. A function, the lambda handler, would be wrapped in a higher order function. This would allow us to attach properties to the function object that specified what resources, such as a Dynamo Table, or imported Lambda Functions would be needed. When the resulting function was invoked clients for each of these resources would be constructed based on the environment variables and attached to the current context.
We now had a tool that generated CloudFormation templates from our code. Additionally as long as that we always relied on our framework to initialize clients like Dynamo we knew that we'd never miss environment variables ever again. All that was missing as a solution to the problem that had actually started this, testing with transitive dependencies. Because the template was being generated from our code we added hooks to the template generator and defined new generators that allowed us to intercept the template generation process when we hit a reference to an outside resource. Rather than emitting an import statement to reference a lambda defined in another stack, we were able to create a new lambda in the current stack and mock it's behavior during tests. The result is that we could continue to have isolated testing with real instances of the infrastructure.
Part 3. Prolific Environment Variables
The system all came falling down about 18 months after we built it. As designed it only concerned it's self with Clients for resources like S3, Dynamo, and Lambda. We'd realized that we needed a solution to composition and bolted one on, but some fundamental issues with the design were starting to come to light. In particular the design of the composition system led to an explosion of environment variables that were needed.
The solution was to go back to the drawing board on dependency injection. Rather than just throwing something together quickly
we would need a proper DI tool at the core of this system. What we came up with was a package we called context-injector. It was
actually copmpletely independent from our CloudFormation Template generator but powered it.
Much like Dagger our dependency injection tool was based on the understanding that while there was value in using dependency injection, especially around being able to stub out resources for things like databases. We didn't need the resolution step that a normal DI system used. Intead we'd just construct a complete dependency graph manually. You can see this in the code below.
By directly referencing the dependencies providers directly constructing a component was trivially easy. It was implemented as a depth-first recursive algorithm, first creating all the dependencies and then creating the component, passing in the constructed dependencies. That looks roughly like this.
The context argument that is being passed as this to the provider.construct function is the context argument to the lambda function.
It's got useful stuff on it, and it allows us to isolate each run of the function. For instance a singleton can cache the resulting component
in a WeakMap with the context as the key.
So now we've written our own dependency injection framework but how does it solve for our problem of too many environment variables? What's missing
from the code above is the metadata that we also attached to each of the providers. There are then methods to read the metadata of an entire tree.
So one of our lowest level providers is env and it looks like this.
That call to with is attaching metadata to the provider. When we go to construct our cloud formation template we can look for all of the metadata
with the envKey and use it to construct the set of enviornment variables. We use metadata for envoironment variables and permissions. This allows us
to write self-contained providers that expose the things that need to be added to the template.
Part 4. Enter Rollup
The inital version of our tooling had been built on top of glup, but we wanted to minimze our bundle size to decrease the cold-start time of our lambda functions, to do that we turned to rollup. With rollup we could really start to think about our systems as a graph. The entry point would be a lambda function since these represented the API that other stacks would consume. We would leverage our graph of providers, starting with the provider for the lambda implementation and use it to discover dependencies on other AWS resources. Adding a new resource to a stack was as easy as writing code that depended on it. We could share libraries that exported Providers which created their own resources in the consumer's stack.
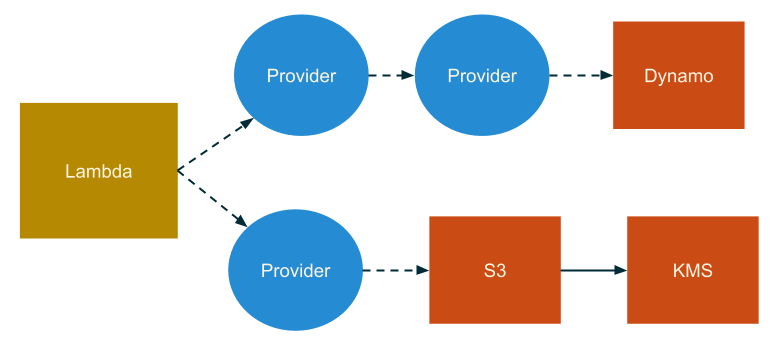
Around the end of 2020 we had all of these peices in place and saw what was in effect an explosion in productivity. Developers could re-use software components and even if those components depended on concrete resources like a database they would automatically get access to that database.